Consistent Hash Rings Explained Simply
Consistent hash rings are beautiful structures, yet often poorly explained. Implementations tend to focus on clever language-specific tricks, and theoretical approaches insist on befuddling it with math and tangents irrelevant.
This is an attempt at explanation - and a Python implementation - accessible to an ordinary high-schooler.
Why Hash? #
Fairly often, you need a way to take an item and get back another stored item. For instance, you may want to take a URL and get back the server the website is hosted on.
These cases can be accomplished by a map, which effectively acts like a phonebook - you look up names (or keys), and you get back information (or values) about the name.
An index in a book, too, is a map - given a word, it can take you to the exact page the word is referenced.
All a map is is a way to take something that can point to another item, and then return that second item.
Computers can pull this trick off too: they take a value, and store it at a location in memory. Then, given a key, they somehow use that key to figure out the address of that memory location, go to that location, and return that value.
Figuring out the address is called hashing, and maps that work like this under the hood are called hash tables. Memory locations are called buckets.

Problem 1: Finite Memory #
Hashing just takes a key and generates a potentially infinitely large number (a hash) which is supposed to represent a memory address. Real computers, though, only provide a finite amount of memory to programs.
A direct one-to-one between the hash and the memory in your computer is impossible in most circumstances.
The solution is to sidestep it:
- Know all your possible memory locations in advance.
- Order them sequentially. Label them 1, 2, 3, etc. in your head if necessary.
- Take a key, compute the hash, and divide that by the number of memory locations you have.
The memory location with the same label as the remainder you compute is where you store your value.
If I have 10 memory locations, and the hash for my key is 1,013, then I compute 1013 % 10 (i.e. the remainder) = 3, and thus put the value in the 3rd memory location.
Every time I need to look up the value, I just do these steps again. Every time I need to store a new value, I just do these steps again. Rinse, lather, repeat. The value is always stored in the hash % bucketsth location.
For many real-world applications, this is actually quite sufficient. Here’s a bare-bones no-frills implementation of a hash table with just two lists:
class HashTable(object):
def __init__(self):
# start with a list of locations
self._values = [None for item in xrange(256)]
self._keys = [] # start with no keys, as is right
def hashfunc(self,key):
# our hash function.
return hash(key) % len(self._values)
def __getitem__(self,key):
''' Implements lookup i.e. q[s] calls q.__getitem__(s) '''
if self._values[self.hashfunc(key)] is not None:
return self._values[self.hashfunc(key)]
else:
return "Not found"
def __setitem__(self,key,value):
'''Updates and adds i.e. q[s] = 2 calls q.__setitem__(s,2) '''
if value is None:
raise ValueError('None is not permitted as a value.')
# if there's never been a value, then add key and set value
if self._values[self.hashfunc(key)] is None:
self._keys.append(key)
self._values[self.hashfunc(key)] = value
# if there **is** a value already, then update the old one
else:
if key in self._keys:
self._values[self.hashfunc(key)] = value
A much more robust implementation handles what happens if you have more than 256 keys, or if a hash function generates the same hash for two different keys. Both problems are well solved, however.
Problem 2: Disappearing Buckets #
An ordinary hash table relies on the presence of a fixed, constant, never changing number of locations. There are times when this is not the case.
Let’s understand what happens if the number of locations n is changed. We’ll walk through our steps:
- Start with 10 locations and a key that hashes to 1013.
- Store the value at the
1013 % 10 = 3rd position. - Change the number of locations to 9.
- Try to look up the same key the same way. Now we return data in the
1013 % 9 = 5th location, which is wrong!
So now we’re returning the wrong values, which is never ideal. Imagine typing in https://www.google.com into your browser and hitting Facebook!
Situations like these can occur sometimes. They can occur in content delivery networks, which copy websites across multiple servers and need to know which server to return when asked for a particular URL.
Sometimes servers die. Sometimes more servers get added. Either way, the number of locations - the number of servers - changes.
With regular hashtables, the only way to ensure data consistency is to:
- Get every key, including those whose values are in the lost location.
- Compute the old values i.e.
hash % old number of locationsto find the original values. - Move all the values over to new locations using
hash % new number of locations - Start using the new formula for all requests.
This ‘remapping’ gets really tedious really fast, especially if your locations die or increase at an alarmingly fast rate and you keep repeating these steps.
For 2,000 keys spread across 100 locations, you need to move 1,800 keys across 99 locations just because 1 location with only 20 keys goes down.
Is there a better, less expensive way?
Yes, There Is A Better Solution #
The problem of mimicking a hash table when the number of locations are constantly changing was exactly why consistent hashing was invented.
Consistent hashing, in a nutshell, does this:
- Stop trying to keep one value at exactly one location. Let one location house multiple values from multiple keys.
- Don’t number your locations consecutively. Give them effectively random numbers between 0 and infinity.
-
Don’t compute
hash % number of locations. Instead, find the smallest location number greater than your key’s hash, and put it there. - If your hash is greater than all locations, put it in the lowest-numbered location.
I start with five locations randomly numbered 1, 20, 41, 1024, 2016. Given a key with hash 1013, I put it in the location numbered 1024. Given a key with hash 2017, I put it in the location numbered 1.
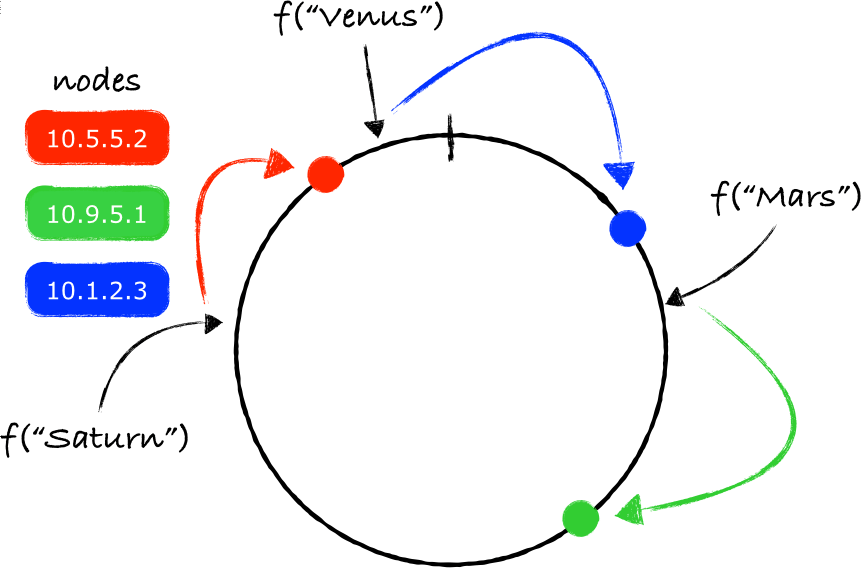
Why is this better? Let’s see what happens when we walk through our steps:
- Start with five locations randomly numbered 1, 20, 41, 1024, 2016. Location number 1024 disappears - we’re left with 1, 20, 41, 2016.
- All keys with a hash greater than 2016 are still mapped to 1. They don’t need to change.
- All keys with hashes lower than 20, or 41, or 2016 are still mapped to locations 20, 41 and 2016. They don’t need to change.
- Only keys with hash greater than 41 and less than 1024 need to change. The new smallest location greater than these numbers is now 2016. Thus, they just need to be remapped to 2016.
The difference is marked when you take the same example from last time:
For 2,000 keys spread across 100 locations, you now need to move only 20 keys to a new location if 1 location with only 20 keys goes down.
This is the main benefit of consistent hashing: you now no longer need to move so many things just because one location has disappeared. It basically reduces your headache.
For locations that ‘die’ frequently - a MySQL slave goes down, for instance - you can now sleep easy knowing you’re not going to bring down your network because of one failing computer.
Important Clarifications #
Now that you understand the process of consistent hashing, some clarifications are necessary:
-
Consistent hashing does not solve the problem of looking things up completely by itself. It only solves the problem of knowing where keys are most likely to be located.
Because a single location may now hold multiple values from multiple keys, once a key knows to go to that location, additional logic needs to be provided to return the exact location.
A ‘location’ in this instance could be a computer server - when keys come to it through consistent hashing, this server looks up its much smaller, local hash table to return the value.
-
In practice, the number for each location is typically not randomly generated. Instead, each location usually has a name (e.g. mylittleserver.pony.com, to continue our server example), and this name is hashed to get back an effectively random number. That’s why it is called consistent hashing
This simplifies a lot of implementation details. You can certainly have consistent hashing with purely random numbers - indeed, it can actually improve distribution of requests to each location. But this is mostly a case for advanced optimisation.
How to Implement A Consistent Hash Ring #
This is the technical portion of this post.
Consider our requirements:
- We need a structure that is capable of searching for values.
- We need a structure that is capable of maintaining a sorted ordering.
Two elementary data structures meet these criteria when paired with binary search:
- A sorted list, and
- A binary search tree
Given a sorted list, a simple workflow might look like this:
- Start with an empty structure.
- Given the hostname of a server, hash it to get back a numerical value.
- Insert the numerical value in your list, and save the name of the server somewhere else.
- If a hostname is removed, simply pop it from its current location.
- If a hostname is added, place its hash in sorted order with the older hostname’s hash.
- Now you’re given a key. Compute its hash, and use a variation of binary search to find the hostname with the nearest hash. Return that hostname.
And that’s it! That’s all you need.
In this post, I have chosen to implement it as a binary search tree. There are a few reasons, most prominently because I wanted to eschew using anything more sophisticated than basic Python, and using a sorted list efficiently would mean resorting to Python’s bisect.
So, without further ado, here follows a simple recursive implementation:
class SubTree(object):
'''
A class that implements a subtree in our binary search tree. This subtree can be either a node, a node with leaf nodes, or a node with other other subtrees as children.
Methods for removal and insertion are defined here. Lookup is not provided as we only care about that when we have access to a dedicated root node.
'''
def __init__(self, value, left=None, right=None):
'''
@param: value [Any]: The raw value you wish to insert. Must implement comparison.
@param: left, right [Node]: Left and right children of this node.
'''
self.value, self.key = value, hash(value)
self.left, self.right = left, right
How to handle insertion:
def add_child(self, value):
'''
Recursively add a child node with the defined value.
Duplicate values are excluded in this tree.
'''
key = hash(value)
if key == self.key:
return
if key > self.key:
if self.right is None:
self.right = SubTree(value)
else:
self.right.add_child(value)
if key < self.key:
if self.left is None:
self.left = SubTree(value)
else:
self.left.add_child(value)
How to handle deletion (here, find_in_order_successor() just finds the next higher-valued key):
def remove_value(self, value):
'''
Removes a value from this node and its subtree.
Returns the new node that should take the place of the node
that was removed.
'''
key = hash(value)
if key == self.key:
# if leaf node, remove oneself
if self.left is None and self.right is None:
return None
# the following two cases return whichever child node is
# extant for a one-child parent.
if self.left is None and self.right is not None:
return self.right
if self.right is None and self.left is not None:
return self.left
# case where neither left or right child is empty
if self.right is not None and self.left is not None:
# copy the value of the first in-order successor,
# then delete the first in-order successor node.
self.value = self._find_in_order_successor()
self.right = self.right.remove_value(self.value)
return self
else:
if self.left is not None:
self.left = self.left.remove_value(value)
if self.right is not None:
self.right = self.right.remove_value(value)
return self #
Now that we have a bare basic binary search tree, let’s finally implement our hash ring:
class ConsistentHashRing(object):
'''
A wrapper around the SubTree class that lets you manipulate the whole tree at once.
This class provides access to the root node, and enables you to search the tree
for the closest match to a value. Iteration and length methods return all stored
values in the tree, however.
Values added to this ConsistentHashRing _must_ be hashable.
'''
def __init__(self, value=None):
self.head = None if value is None else SubTree(value)
Addition and deletion have already been implemented for self.head – we just need to call those appropriately:
def add_node(self, value):
''' Add a value to the tree as a whole. '''
if self.head is None:
self.head = SubTree(value)
else:
self.head.add_child(value)
def remove_node(self, value):
'''
Remove a value from the tree.
Only exact matches may be removed - values not in the tree
are ignored.
'''
if self.head is None:
return
self.head = self.head.remove_value(value)
The meat of the matter, however, lies in how we find the nearest upper neighbour:
def find_best_match(self, value):
'''
Search for closest match - if exact value exists, it shall return that value, otherwise it will return the closest
value. If the tree is empty, it returns None.
Note that 'closest match' here translates to first bigger value than value passed in as parameter here. If an exact
match is found, it returns that.
'''
key = hash(value)
current_node = self.head
best_match, best_match_key = None, float("inf")
# if tree is empty, return None
if not self.head:
return None
# if tree is not empty, walk through the binary search tree, and update the best_match to reflect the closest but
# larger value encountered.
while current_node is not None:
# exit if exact match is found, returning that value
if current_node.key == key:
return current_node.value
# if number is bigger, check if it is closer to our target value than the last number, and choose to update
# accordingly
if current_node.key > key:
best_match = current_node.value if abs(current_node.key - key) < abs(best_match_key - key) else best_match
best_match_key = hash(best_match)
current_node = current_node.left
continue
if current_node.key < key:
current_node = current_node.right
continue
# best_match can still be None if all values in the BST are smaller than the submitted value. In that case,
# we always return the smallest value in the BST, in line with the principles behind consistent hashing.
if best_match:
return best_match
else:
# will always return the smallest value in the BST
return self.head._find_minimum_subtree_child_value()
And that’s it! See the Git repo, complete with tests.